量子機械学習 | 曽我部研究室 SogabeLab 国立大学法人電気通信大学│AI 人工知能 量子
RESEARCH
研究内容
量子機械学習
量子(回路or機械)学習のVC次元をはじめて確立、過学習しにくいことを検証
世界的な権威であるACM学会発刊量子コンピューティング雑誌に論文掲載
◆量子機械学習器は過学習しにくいという性質を、詳細な数値実験と統計的機械学習の理論を通して示した
◆この成果がACM (Association for Computing Machinery) 発行の学術雑誌「ACM Transactions on Quantum Computing」に掲載
【概要】
曽我部 東馬 准教授らの量子アルゴリズム研究チームは、量子機械学習器は過学習しにくいという性質を、詳細な数値実験と統計的機械学習の理論を通して示しました。そして、この成果は世界的な権威であるACM (Association for Computing Machinery) が発刊する学術雑誌「ACM Transactions on Quantum Computing」に掲載されました。
【背景】
AIの社会実装が進み、より複雑な課題解決への活用が期待される中で、機械学習においてAIモデルの精度向上を阻む要因となっているのが「過学習」です。過学習とは、学習精度がある一定の精度まで向上すると、以降は未知のデータへの対応力を失ってしまう現象です。従来型AIでは、正則化やドロップアウトを行い、学習に制限を設けることで過学習を回避してきました。そのため古典コンピュータにおける機械学習では、過学習がモデルの精度向上のボトルネックとなっています。一方で量子コンピュータでは、量子の特性により過学習が抑制される性質があることが示唆されていましたが、理論を含む詳細な検証はこれまでなされていませんでした。今回の論文では量子機械学習器は過学習しにくいという性質を詳細な数値実験を通して示し、その根拠となる理論を世界で初めて提示しました。この成果は「ACM Transactions on Quantum Computing」に掲載されました。
【手法】
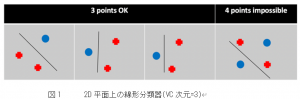
統計的学習理論におけるVapnik-Chervonenkis(VC)理論は、VC次元の観点から汎化誤差境界を得るために使用することができます。VC次元とは,仮説集合の分類能力を記述する組み合わせプロパティです。これは、二項分類において任意に分類できるデータポイントの最大数です。例えば、2次元の入力空間では,線形分類器は最大で3点を切り分けることができますが、4点を切り分けることはできません。このことから、2次元空間における線形分類器のVC次元は3に等しいと言えます。
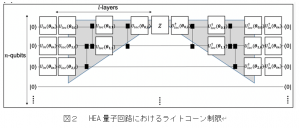
また、量子回路構造を考慮することで、量子回路学習(QCL)仮説集合のVC次元の上限を得ることができます。この上限を用いて、QCLの汎化化誤差の上限を確立することができます。この上限は、テンソルネットワークの光円錐(ライトコーン)の上限であるHardware Efficient Ansatz(HEA)の局所性と単一性を考慮することで、さらに改善することができます。これにより、HEA量子回路のモデルの複雑さが定量化され、機械学習アプリケーションにおける過学習を避けるためのモデル選択に利用することができます。
【成果】
量子コンピュータは古典コンピュータとは全く異なる性質で動くため、古典コンピュータ上で成り立つ性質が量子コンピュータでも同様に成立するのかどうか、解明されていない部分が未だに多くあります。そのため本研究では、様々な量子アルゴリズムで採用されている汎用的な量子回路について、量子ビットの数と量子回路の深さなどがモデルの表現力と過学習にどう影響するかを研究しました。その結果、量子回路の深さを増加させ(古典ニューラルネットワークを多層にすることに対応)パラメータを増加させると、ある地点でモデルの表現力が飽和することを、様々な数値実験で見出しました。モデルの表現力が飽和するということは、回路パラメータを増加させてもそれ以上モデルが複雑化せず、結果、過学習が起きない事を意味します。さらに、この事実の理論保証を与えるため、本研究では、モデルの複雑性の指標であるVC次元(※1)が上限値をもつことを証明しました。このことは、訓練誤差と汎化誤差の差分の拡大が進まないことを意味し、つまり量子回路は過学習しにくいことを示しています。今回の成果は株式会社グリッドの協力と共同研究の結果です。
※1:VC次元は、学習モデルが完全に分類することができる最大のデータ数を数値化したもの
【今後の期待】
今回の研究成果は、機械学習の分野において量子コンピュータを使う意義と利点を補強するもので、量子機械学習の実用化に向けた大きな足掛かりになると期待しています。
今後も引き続きコンピュータサイエンスの分野において研究を続け、学術分野への貢献と、量子コンピュータの社会実装に貢献して参ります。
【慶應義塾大学 量子コンピューティングセンター センター長 山本 直樹氏のコメント】
今回の研究成果の意義を正しく理解するには、人工知能(AI)研究に関する歴史を簡単に振り返る必要があります。いうまでもなく、現在AIは産業からエンタメまであらゆる分野で覇権をふるっています。一方で、この猛威が3回目のブームであるという事実を知っている人はさほど多くはないかもしれません。AIは、いままで2度の盛衰を経験しているのです。
最初の栄華は1950年代~1960年代に起こりました。AIの道具として、人間の脳機能を模倣するニューラルネットワーク(NN)がよく使われます。これの初期提案がなされたのがこの時代です。しかしごく簡単なタスクしかこなせないと批判され、研究は下火になりました。2度目のブームは計算機が普及してきた1980年代~1990年代です。しかしNNの有効性を示すにはまだ計算機パワーが足りず、結局、またブームは去りました。現在のブームは2006年、NNがディープラーニングと名前を変えて華々しく再登場したことが契機でした。ついに、AIがその強力な情報処理能力を発揮するための計算機デバイスが使えるようになったのです。
ではブームの谷間、AI研究は真に停滞していたのでしょうか。そうではなく、まさに雌伏という言葉の通り、その数理的基礎研究が着々と進行していました。とくに、今回の成果にあるVC次元という概念が、第1次ブーム終焉後の1971年、当時ソビエト連邦の研究者であったVapnikとChervonenkisによって提案されました。これは大雑把に言うと、NNの情報処理能力を測るものさしです。この量が大きすぎるNNは過学習してしまいます。つまり、NNの情報処理能力が高すぎると、(期末試験を乗り切るために教科書を丸暗記する学生のように)未知データに対応できなくなってしまいます。この意味で、大きすぎないVC次元をもつNNを用いるべし、という重要な指針が得られたわけです。
現在華々しく利用されているAIを支えているのはこういった基礎理論で、実は、それらは比較的早期に発見されていました。例えば、NNの訓練法としていまでも標準的に使われる誤差逆伝搬法が甘利博士によって提案されたのは1966年です。また、上記の過学習問題に対する指針のさきがけとみなせる情報量基準が赤池博士によって提案されたのは1973年でした。CybenkoによるNNの万能近似定理が証明されたのは1989年で、またVapnikの統計的学習理論が広く知れ渡ったのは、彼が渡米しAT&Tに就職した1990年以降でした。
以上の話から、今回の成果の意義を理解することができます。量子計算機デバイスは、近年急速に発展していますが、まだまだ小さく脆弱です。しかし、規模がさらに拡大し、エラーが十分に抑えられ安定動作できるようになったら、色々な実問題において、量子計算機は現在使われている計算機を上回る情報処理能力を獲得するでしょう。そしてAI分野への応用においては、現行版とは全く異なる構造をもつNN、すなわち量子NNが使われることになります。すると上述したNNの事例から類推できるように、量子NNの数理的基礎研究が将来の量子AIを支えることになるでしょう。事実、最近、量子NNに関する重要な成果が世界中の有力研究機関から続々と発表されています。その中で、今回の論文は、量子NNのVC次元と過学習問題をはじめて正面から扱ったものです。素晴らしいことに、量子NNはVC次元がさほど大きくならず、過学習が起きにくいということが示唆されています。
量子AIのパワーはまだ未知数です。しかし、数理的事実は不変です。将来、量子NNのVC次元をはじめて計算したのは「2021年のあの論文だったね」と回顧することが楽しみです。
【論文情報】
タイトル:“On the expressibility and overfitting of quantum circuit learning”
著者:C-C. Chen, M.Watabe, K. Shiba, M.Sogabe, K.Sakamoto and T. Sogabe
掲載誌:ACM Transactions on Quantum Computing,2,8,p1–24(2021)
公開日: 2021年7月9日
本誌リンク:https://doi.org/10.1145/3466797
■下記のニュースも併せてご覧ください。
電気通信大学ニュースリリース:https://www.uec.ac.jp/news/announcement/2021/20210726_3571.html