深層強化学習を用いたAGV搬送システムの最適化 | 曽我部研究室 SogabeLab 国立大学法人電気通信大学│AI 人工知能 量子
RESEARCH
研究内容
深層強化学習を用いたAGV搬送システムの最適化
【概要と背景】
近年、 生産システムの柔軟性や効率の向上のために荷物を自動的に運べるAGV(Automated Guided Vehicle)が広く用いられています。AGVを効率良く運用するためには、搬送経路の決定など多くの計画問題を解決する必要があります。計画問題の解決に向けて、様々な最適化手法を利用した研究がされていますが、決定版といえるようなアルゴリズムが存在しないというのが現状です。さらに従来の最適化手法はレイアウトや工程の変更の度にアルゴリズムの再実装が必要という課題があります。そのため、生産環境や要件の変化に対応できるような汎用性や自己学習機能がアルゴリズムに求められています。
そこで本研究では、AGV搬送システムにおける設計問題へのアプローチとして、深層学習の推論機能と強化学習の最適化機能を融合した深層強化学習を提案します。強化学習とは、学習者が環境との相互作用を通して、将来的な価値(報酬)が最大となる行動ルール(方策)を推定する機械学習法の1つです。深層強化学習の特徴として、ニューラルネットワークが訓練データに基づいて独自の特徴を自動的に発見することができ、多くの最適化問題に適用できる可能性があるため、1つの問題のみに最適化される数理計画法やメタ戦略などの従来手法よりも汎用性に優れていると言えます。
【手法】
■関連研究
強化学習を用いて、複数のAGVを誘導する自律分散方式の研究[1]や、TSPと呼ばれる経路計画問題において、複数の異なる環境に対して、同一の深層強化学習アルゴリズムを適用しても、最良解が得られたという報告がされています[2]。AGVの将来のタスクを予測し、最適化を行った研究[3]などありますが、深層強化学習をAGV搬送システムに応用した事例が少ないのが現時点での実情です。
■ 提案手法
本研究では、深層強化学習の標準的な手法の1つであるDQN(Deep Q Network)を用います。 DQNは、行動の価値を定める関数を、ニューラルネットを使った近似関数で求める手法です。実験の手順をFig.1に示します。実験では最初に、環境Aにおいて試行錯誤を繰り返し、理想的な搬送を行うことが出来るまでエージェントの学習を続けます。その後、行動選択の役割を果たすニューラルネットワークの重みを保存します。次に、初めに学習した環境とは異なる環境B、Cに対して、保存したニューラルネットワークの重みを適用し、行動選択を行わせます。このようにして複数の異なる環境に対して学習済みネットワークを適用することで、深層強化学習における推論機能がどれほどの汎化性能を持っているかを検証します。

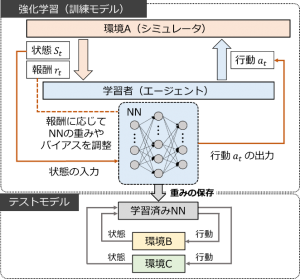 Fig.1: 実験手順の概要図
Fig.1: 実験手順の概要図
■シミュレーション実験
実験環境
Fig.2(a) に示すAGV搬送システムを仮定し、生産シミュレーションモデルを作成しました。4台の AGV がレーンに沿って周回し、3種類の荷物を搬送します。AGVは一方向のみに進行可能であり、すれ違うことは出来ません。
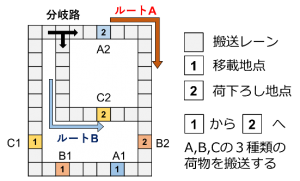 Fig.2: 訓練モデルの概要図
Fig.2: 訓練モデルの概要図
AGVの状態や各移載地点における荷物の有無を環境の状態変数として扱います。AGVはどこの荷物をどの経路で搬送するかを行動として選択します。Fig.2を訓練モデルとして最適化と学習を行った後に、Fig.3に示す移載地点の位置や順番を変えたモデルにおいてテストを行います。
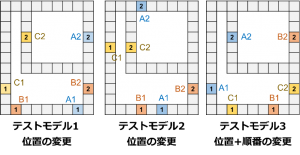 Fig.3: テストモデル1-3の概要図
Fig.3: テストモデル1-3の概要図
【成果】
1000秒間のモデル稼働を一連のエピソードとして検証を行いました。ランダムに行動を選択したエピソード10回分の平均搬送量と、筆者のドメイン知識を用いて作成したルールベースにより行動を選択した時の結果をTab.1に、また、DQNによる学習の様子を、横軸をエピソード数、縦軸を搬送量としてFig.4に示します。結果から、提案手法はルールベースによって実測された搬送量123個に収束していることが確認でき、人間のドメイン知識と同等のアルゴリズムを学習できたと考えることが出来ます。
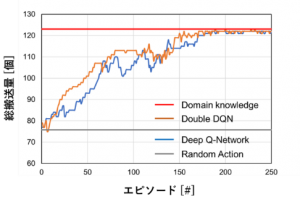
 Fig.4: DQNの学習曲線 Tab.1: 手法やモデルごとの総搬送量
Fig.4: DQNの学習曲線 Tab.1: 手法やモデルごとの総搬送量
また、位置のみが変化したテストモデル1、2においては、訓練モデルとほぼ同等の搬送量を達成しました。一方で、移載地点の位置と順番を変えたテストモデル3では、他のモデルと比べ、大幅に搬送量が減少しました。これらの結果から、学習済みNNは簡単な環境の変化に対しては、柔軟に行動を選択することが出来たと言えます。また、学習済みのアルゴリズムを適用することで人間や他のアルゴリムにより、何十倍以上の早さで同様の結果が得られるようになると考えられます。
【結論と今後の課題】
本研究では、AGV搬送システムにおける設計問題に対して、深層強化学習による最適化法を提案し、シミュレーション実験によってその手法の有効性と汎用を確認しました。
課題としては、深層強化学習による最適化によって得られた解の精度を相対的に評価できていないため、厳密解または近似解を算出し比較を行う必要があります。
【参考文献】
[1] M. Nagayoshi, et. al, JACIII 21(5), 948-957, 2017
[2] I. Bello, et. al, ICLR 2017, arXiv:1611.09940
[3] Dong Li, et. al, arXiv:1909.03373vl, 201