April 2022 | 曽我部研究室 SogabeLab 国立大学法人電気通信大学│AI 人工知能 量子
RESEARCH
研究内容
April 2022
 Title
Title
Magnetic control of tokamak plasmas through deep reinforcement learning Resource Nature , volume 602, pages414–419 (2022)
Author Affiliations: DeepMind, London, UK ; Swiss Plasma Center – EPFL
📄Resource https://www.nature.com/articles/s41586-021-04301-9
🔎Points
- トカマク型核融合炉は持続可能なエネルギーリソースとして注目されている。核融合炉のプラズマ電流制御は、実社会において最も複雑で挑戦的な課題の一つである。これまではオペーレーターの経験によりPID制御で対応してきたが、PID制御の設計には長い時間がかかり、さらに目標となるプラズムの形状が変わる度に、新たにゼロから設計し直さないといけないという問題があった。そこで、著者らは深層強化学習を用いて19個の磁気コイルの制御を学習し、様々な特徴のあるプラズマを生成することに成功した。
- 物理シミュレーターを使用しているので、データの取得は非常に遅い。それを補うために、少ないデータから推論能力の高い深層強化学習アルゴリズム:MPO (maximum a posteriori policy optimization)を用いた。
- MPOアルゴリズムはactor-criticの形を取っている。実際に学習済みのモデルをリアルの核融合制御に応用する際にはActorネットワークしか使わないので、ActorとCriticのニューラルネットを工夫した。具体的には、Actorの方は短い浅いNNを使い、Criticの方は時系列推論が得意である大きめの再帰型NN(RNN)を採用した。
- 将来の展望として、多目的強化学習アルゴリズムを用いることによって学習効率と推論能力の向上が期待できる。
💬Questions or comments
- 報酬関数の要素が非常に多いため、本来はベクトル(すなわち多目的)として扱う必要があり、論文では無理矢理、スカラー化しています。この簡略化によって学習効果に負の影響が出ているかと思われます。
- 核融合の安全性は、第一に考慮すべき要素かと思います。この論文はコイルの電流最大値を設定することにより安全性は担保できていますが、最大値になる度に装置が頻繁に中止と再起動をスイッチする必要があります。より合理的な制御を行うために、このような最大値にほぼほぼならないようなリスク考慮型強化学習アルゴリズムの開発が必要かと思いました

Title
Improved optical properties of perovskite solar cells by introducing Ag nanopartices and ITO AR layers
Chen, Y., Du, C., Sun, L. et al., Scientific Reports, volume 11, 14550 (2021)
📄Resource https://doi.org/10.1038/s41598-021-93914-1
🔎Points
- 近年、ペロブスカイト太陽電池の光吸収層内に貴金属ナノ粒子を埋め込むと、局在表面プラズモン共鳴(LSPR)効果により光吸収が増加することが報告されている。また、デバイス表面にグレーティング構造による反射防止(AR)層を導入することでもデバイスの光学特性が変化することが知られているが、著者らが調べた限りでは、グレーティングAR層とプラズモンナノ構造の両方を導入した研究はほとんどない。そこで著者らは、COMSOLによるシミュレーションで5種類のデバイス構造を比較し、グレーティングAR層とプラズモンナノ構造の相乗効果を確認した。
- 短絡電流密度に対するデバイスの光学特性の影響を考慮するため、半導体モジュールとRFモジュールを使用して計算した。また、金属ナノ粒子やAR層のグレーティング構造のサイズや周期回数などのパラメータは、GAを用いて最適化した。
- 貴金属ナノ粒子の材料としてAg、ペロブスカイトの材料としてCH3NH3PbI3を使用した場合、銀とヨウ素が反応してAgIのような絶縁性錯体を形成し、デバイスの性能が著しく低下することが知られており、解決策としてTiO2をAg表面にコーティングしたシェル構造を用いる試みが研究されている。著者らはTiO2シェルの厚さを変化させた際のデバイス性能への影響をシミュレーションし、厚さが12nmの場合でも、厚さが0nm(AgIが形成されないと仮定した場合)と比べてJscが0.3 mA/cm^2程度しか低下しないことを確認した。
💬Questions or comments
- Agのナノ粒子は面内での周期構造を考えていますが、垂直方向には1つ(1層)のみです。垂直方向に何層かAg粒子が埋め込まれた状態では、光学特性がどのように変化するのか気になりました。
- Agのナノ粒子は球と立方体の2パターンで比較していますが、ITOのARグレーティング構造は円柱のみです。計算時間の関係で単純な形状にしたと考えられますが、例えば半球や円錐などによるモスアイ構造を取り入れると、反射防止としての性能は向上すると思われます。

Title
SimPO:Simultaneous Prediction and Optimization
📄Resource https://arxiv.org/abs/2204.00062
🔎Points
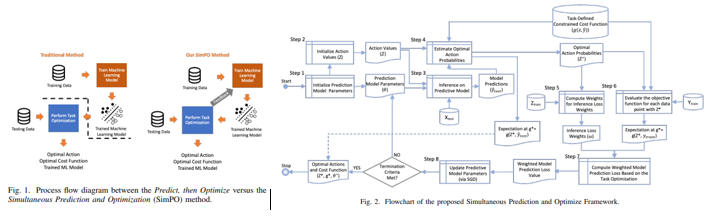
- In the traditional process, the ML models are first trained against a loss function, then a separate optimization solver is applied to minimize or maximize a defined optimization objective. As a result, the predictions generated by the model results in an output which may influence the optimization process to produce a sub-optimal solution. This paper purposed a method that considers a joint weighted function between the loss of prediction error and the optimization task loss.
- This paper aim to learn a model based upon an end-to-end objective that the user is ultimately trying to accomplish. That is, the ML process is predicted directly from the raw input.
💬Questions or comments
- Joint weighted function between the loss of prediction error and the optimization task loss helps to improve the users objectives, but how much does it improve the result to compare with it combined calculation cost?
- Using the same traditional stochastic gradient descent to update and fixed data set does it handle the real-world problems that author add for the future work?
- It may be future machine learning technology. This is because this paper targeting what ordinary users want from AI.
Title
Beyond action valuation: A deep reinforcement learning framework for optimizing player decisions in soccer
Pegah Rahimian, Jan Van Haaren, Togzhan Abzhanova, MIT sports sloan conference(2022)
🔎Points
- ゲーム中の各状況下における生のトラッキングデータを受け取り、ピッチ全体での最適なボールの到達地点を生成する、end to endの深層強化学習モデルを提案した。この方法を用いることで、コーチやプレーヤーは過去の履歴データから実際の行動を分析して今後の戦術を立案することができ、また試合の前に最適な選択の結果を評価することができる。
- 具体的にはチームごとに現状の戦略と最適方策を分析し、現在の戦略が最適方策とどのくらい乖離し、また最適方策をとった場合にどのくらい効果が見込めるのかを推定する。
- 現在は試合のデータから各チームの戦術方針を分析し、チーム全体の評価(最適な戦術を選択した場合の予測と評価)を主に行っているが、今後は各チームの戦術方針に応じた選手一人一人の試合への貢献度を評価する方向へ拡張していきたい。
💬Questions or comments
- 報酬関数の設定方法が興味深かったです。セットプレー方式のアメフトに比べて、サッカーは流動的なスポーツであるため、プレーの切れ目やそれぞれのプレーがどんな目的でされているのか判断するのは難しいですが、ボール保持の状況を4つのフェーズに分け、それぞれのフェーズに対して報酬関数を決定していました。また最も高い報酬が良いとは限らない(良いプレーをしたからと言って直接得点につながるとは限らない)ため、割引率を用いて調整を行っていました。アメフトの場合でもこれまでは10ヤードを進むことができれば報酬を与える、もしくは得点を獲得したら報酬を与えると設定していましたが、現在の得失点差やフィールドのどの地点から攻撃を開始するかなどを反映した場合、どのような結果が得られるのか気になりました。
- 現状では過去の試合のデータに基づいて評価を行っていますが、リアルタイムでデータを取得できる場合、試合と同時進行で予測や評価ができるのか気になりました。

Title
A Distributional Perspective on Reinforcement Learning(2017)
📄Resource https://arxiv.org/abs/1707.06887
🔎Points
- 行動状態価値Q(s,t)に基づく価値ベースの強化学習において、Q(s,t)を更にN分割の離散分布で表現する深層強化学習モデルを提案した。
- 学習の目的は従来と同様に環境モデルから取得できる報酬の最大化となる。ただし、分布で表現することで不安定な将来報酬によるDQNの振動や発散を抑えられ安定した学習を行えると主張する。
- 学習の速さは離散分布の分割数によって大きく変化し、特に51分割したモデルではDQNと比較しより高い報酬を少ない訓練回数で得られることを確認した。
💬Questions or comments
- 文中では期待値の収束性を成立させるために距離の尺度としてワッサースタイン計量を使う必要があると繰り返し説かれていますが、紹介されているアルゴリズムでは誤差関数にKL発散を用いています。これはワッサースタイン計量では実際の計算が難しいからだそうで、どう影響があるのか気になっています。
- Q(s,t)を拡張する前後でNNのサイズがどう設定されているのか確認できていませんが、環境モデルで試行したフレーム数に対しては高速に学習できても、1回の訓練自体はより時間がかかるように思います。

Title
On the relevance of understanding and controlling the locations of dopants in hematite photoanodes for low-cost water splitting
Applied Physics Letters,119,200501(2021)
📄Resource https://aip.scitation.org/doi/10.1063/5.0066931?via=site
🔎Points
論文を選択した理由(目的)
hematite(Fe2O3)を光陽極としての用いる問題点と改善点について
特に、ドーピングの場所に注目して解説している。なぜ、Fe2O3か?
1)長時間安定である。
2)Eg約1.9~2.2eVであり、効率15%~17%であると理論的に予想
3)earh abundant(地球で豊富)、低コスト、環境にやさしい(良性)
報告が多くある。
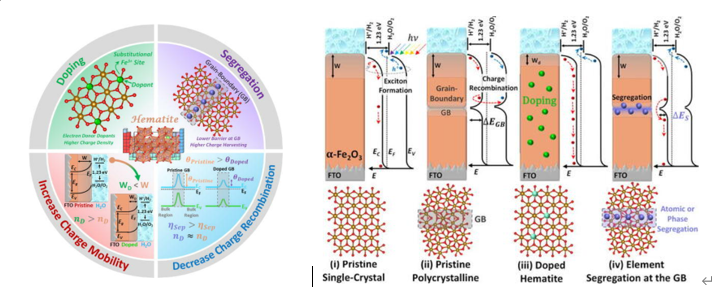
光陽電極の特性改善戦略は、以下の4項目である。
1)Doping
2)Segregation
3)Increase charge mobility
4)Decrease charge recombinationDopingとGrain Boundary(GB)の効果について
4種類のDopingとエネルギーバンドの関係を図示している。
1)均質
2)GBが存在
3)均一のDoping
4)GBにsegregation(分離)具体例として、
Ti,Si,Snドープすることで、電気特性が改善される。
Snのドープの論文において、
どこに、存在するかを報告している。
論文中では、4)で特性を改善していると報告している。
まとめ
粒界の制御と粒界の境界ドープが、
電荷輸送を増強と
GBでの障壁エネルギーを減少をもたらす。
💬Questions or comments
Q1)具体的なDoping効果の測定について?
場所を特定できるのか?
A1)Dopinの場所は、HR-TEMで、構造を確認
Dopingの効果は、電気分解、電気伝導の変化を測定する。Q2)Fe2O3の薄膜作製方法は?
A2)スプレー方法が多い。Q3)LPD(Liquid Phase Deposition)で、SnをDopeすることができるか?
A3)調査中(関連論文があり)
Title
Preparation and characterization of iron oxyhydroxide and iron oxide thin films by liquid-phase deposition
J. Mater. Chem., volume 7, No.9 pages1769–1772 (1997)
Shigeaki Deki, Yoshifumi Aoi, Junko Okibe, Hiroshi Yanagimoto, Akihiko Kajinami and Minoru Mizuhara
📄Resource https://pubs.rsc.org/en/content/articlepdf/1997/jm/a700628d
🔎Points
1. 一般的に金属酸化物薄膜は真空蒸着、スパッタリング、CVD法のようなドライプロセスやウェットプロセスを用いて作製される。これらの手法は真空装置を用いているので薄膜製造が高価になる。
2. これに対して液相析出(Liquid Phase Deposition:LPD)法は、高価な真空装置を用いず、また基板材料やその形状を問わず一定時間溶液に浸漬放置し、金属フッ化物錯体水溶液から析出反応に駆動反応を作用させ、基板上に安定な薄膜として酸化物もしくはオキシ水酸化物を均一に析出・成長させる成膜法である。
3. 本論文ではLPD法で基板上にβ-FeOOH膜を作製し、その後熱処理をすることで酸化鉄膜(α-Fe2O3)を作製している。空気中で基板上に作製されたβ-FeOOH膜を400℃以上の温度で熱処理することで酸化鉄膜(α-Fe2O3)になることを見出した。
4. 将来の展望として、反応溶液に可溶な物質を添加することにより、多成分系酸化物薄膜、複合材料薄膜、ドーピング薄膜等の組成制御した薄膜作製の成膜などが考えられる。
💬Questions or comments
1. β-FeOOH膜を作製するにあたり反応溶液(FeOOH-NH4F・HF)とH3BO3溶液の混合比が具体的に記載されておらず、実際に基板上にβ-FeOOH膜を成膜することがかなり困難であった。
2. 硝酸第一鉄水溶液にアンモニア水を添加することでβ-FeOOHが生成されるが、アンモニア水の濃度や量が記載されておらずβ-FeOOH作製が難しいと感じた。

Title
Linear growth of quantum circuit complexity
Jonas Haferkamp, Philippe Faist, Naga B. T. Kothakonda, Jens Eisert & Nicole Yunger Halpern
📄Resource https://doi.org/10.1038/s41567-022-01539-6
🔎Points
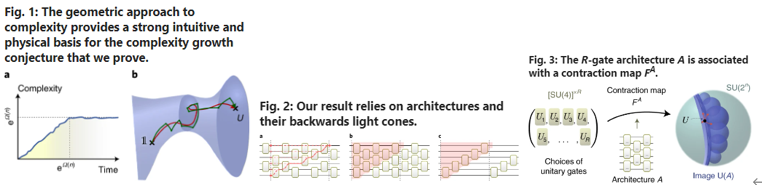
- Mathematical proof for circuit complexity lower bound for random quantum circuit.
- The bound grows linearly up to some constant (the constant scales exponentially with respect to circuit width).
💬Questions or comments
- The lower bound tells us that if we want to construct some other quantum circuit to generate the same state, there is a minimum number of quantum gates required. (Circuit size cannot be improved better than this lower bound)
- As far as I know, the best classical circuit lower bound for NP language is linear with respect to number of input bits. However, the bound given in this work is probabilistic (with probability one that this bound is true). There could be several cases where the bound fails (but these cases has measure zero.)
Title
“Energy management based on multi-agent deep reinforcement learning for a multi-energy industrial park”
Zhu, Dafeng, et al. Applied Energy 311 (2022): 118636.
📄Resource https://doi.org/10.1016/j.apenergy.2022.118636 https://arxiv.org/abs/2202.03771
🔎Points
- Due to the coupling of multiple energy sources and the uncertainty of renewable energy and demand, centralized methods require large calculation and coordination overhead. This paper proposes a multi-energy management framework achieved by decentralized execution and centralized training for an industrial park.
- The proposed algorithm has the following three points, 1.counterfactual baseline (for facilitating agents to learn better policies), 2.a novel reward (designed by Lagrange multiplier method) and 3.an attention mechanism (considering that the increase in the number of agents leads to performance degradation due to large observation spaces)
💬Questions or comments
- The proposed algorithm scores higher than MADDPG in the author’s environment, but how well does it perform in the RL benchmark test?
- Can we apply key points of this algorithm to other MARL algorithms or environments?

Title
Efficient and Stable PbS Quantum Dot Solar Cells by Triple-Cation Perovskite Passivation
Miguel Albaladejo-Siguan,et.al, ACS Nano(2020),384–393
📄Resource https://doi.org/10.1021/acsnano.9b05848
🔎Points
・PbS量子ドットの表面のパッシベーションに3重カチオンCs0.05(MA0.17FA0.83)0.95Pb(I0.9Br0.1)3ペロブスカイト組成を用いることで、これまでのペロブスカイトをパッシベーションとして用いたPbS太陽電池よりも上回る最大電力変換効率11.3%を達成した。
・CsMAFAシェルとPbSコアの間のエネルギー的な配列(PbSコアの伝導帯がCsMAFAの伝導帯よりも0.3eV深い)によって、電荷がPbSコア内にとどめられ、再結合を抑制されている。また、比較的低いエネルギー障壁により、隣接する量子ドット間に電荷輸送に支障がない。この電荷輸送を制限することなく、電荷の閉じ込めによる再結合を減少させたことで上記の優れた性能を示すことができた。
・MAPbI3-PbS QDを用いたデバイスは480時間後に85%と劣化してしまうのに対して、CSMAFA-PbS QDを用いたデバイスは1200時間後に元の性能の96%と劣化が少ないことを示せた。
💬Questions or comments
・第一原理計算を用いて、CsMAFAのパッシベーションしたPbS量子ドットの電荷移動度などを評価してみたいと思った。
・CSMAFA-PbS QDを用いた太陽電池が高い性能を持っている要因は論文で述べられているコアとシェルの伝導帯のエネルギー差によるものだけなのか。
・論文では使用していたMAPbI3-PbS QDのMAとFAの割合を1:5にしていたが、他の割合で行った場合、どのような結果が出るのか。割合を変えることでさらにいい性能が出るのか。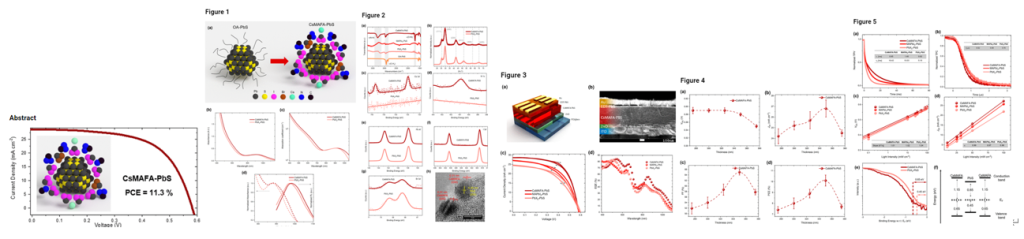
Title
Inverse design of 3d molecular structures with conditional generative neural networks.
Gebauer, Niklas WA, et al., Nature communications 13.1 (2022): 1-11.
📄Resource https://www.nature.com/articles/s41467-022-28526-y
🔎Points
1. グラフやフィンガープリントなどではなく、直接分子の構造を予測できる。
2. 予測精度を上げるには従来の手法であるG-SchNetでは学習データの調整などによってバイアスをかける必要があったが、提案手法であるcG-SchNetではそういった調整なしに従来手法より予測精度の向上が示した。
3. 訓練データ中に同じフィンガープリントを持つ分子が存在しないが、MLモデルは完全に一致する分子の生成に成功しており、化学物質空間の未知の領域を汎化し探索する能力を示した。
💬Questions or comments
1. 原子間の距離をサンプリングしているが、距離だけでなく角度などがないと次の原子の位置が定まらないのではないかと気になりました。
2. 今回はQM9という小さい有機化合物のデータセットと使用していたが、量子ドットなどのデータでも学習が可能ではないか。
Title
Multi-Agent Deep Reinforcement Learning for Dynamic Power Allocation in Wireless Networks
📄Resource https://ieeexplore.ieee.org/abstract/document/8792117
🔎Points
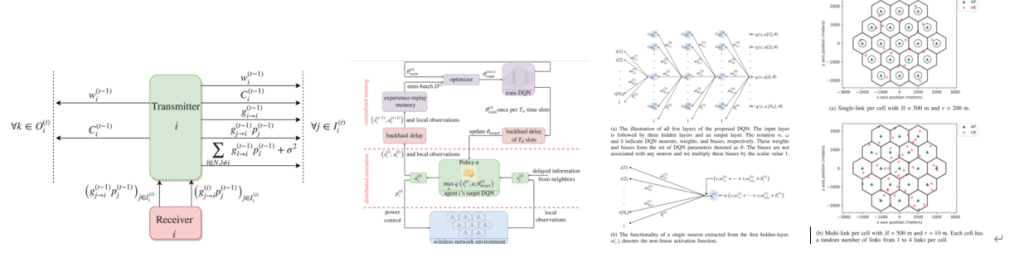
・The proposed approach returns a suboptimal power allocation much quicker than two popular centralized algorithms. In contrast to most advanced optimization based power control algorithms (e.g., WMMSE and FP) which require both instant and accurate measurements of all channel gains, the proposed algorithm only requires delayed accurate measurements of some received power values that are sufficiently strong.
・Each transmitter collects channel state information (CSI) and quality of service (QoS) information from several neighbors and adapts its own transmit power accordingly. The objective is to maximize a weighted sum-rate utility function, which can be particularized to achieve maximum sum-rate or proportionally fair scheduling.
・A jump-start on the training of DQN can also be implemented by using initial parameters taken from another DQN previously trained for a different setup.
💬Questions or comments
・Is it possible to fine-tune even if there is noise or changes in the environment as in the real world?
・This paper used only the DQN algorithm. How much is the dependency, such as when using other modern MARL algorithms?
Title
Model-Free Quantum Control with Reinforcement Learning
V. V. Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsioutsios, and M. H. Devoret
Phys. Rev. X 12, 011059 – Published 28 March 2022
📄Resource https://doi.org/10.1103/PhysRevX.12.011059
🔎Points
・先行研究で行われているモデルフリー量子最適化手法では、平均化によって量子観測の確率性を排除しているが、本研究ではそれを行わず、確率的な二値測定結果を元に安定した学習が行えることを実証している。つまり、実験的にも量子の二値測定結果から再現を行えるのではないかということを提案している。
・シミュレーションに基づく量子制御の主要な手法の本質的な限界であるモデルの偏りの問題に対処するためにend-to-endのモデルフリー強化学習が実現可能な代替手法であるということだけでなく、シミュレーションベースの手法が適用できない領域にも量子制御の能力を拡張する強力なツールとなる。
・QOMDPのエージェントから量子状態s_tとその遷移を隠しているので、RLのフレームワークを変える必要がない。
💬Questions or comments
・QOMDPのエージェントに対して量子状態s_tとその遷移を隠しているのでエージェントはバイナリな値しかobservationを得ないので、その結果RLのフレームワークを変える必要がなくなるというのは面白いポイントだと思いました。
・本論文では様々なtarget stateが用いられていましたが 、これを自分の研究でも報酬関数などを変えることにより再現できるのではないかと思いました。
・量子回路を学習に用いているので、エンタングルゲートのノイズの影響が気になりました。

Title
Reservoir computing using dynamic memristors for temporal information processing
Chao Du, Fuxi Cai, Mohammed A. Zidan, Wen Ma, Seung Hwan Lee & Wei D. Lu
Nature Communications volume 8, Article number: 2204 (2017)
📄Resource https://doi.org/10.1038/s41467-017-02337-y
🔎Points
- 短期記憶性・非線形性を持つ素子としてWOxメモリスタを用いることで、リザバーコンピュータにおけるリザバー層を実現し、手書き数字認識と2次非線形システム問題を通してその性能を実験的に検証した。
- パルスの数が同じで、時間的順序のみが異なる入力データを与えた場合、その出力は時間的順序の違いに対して敏感に反応しており、十分分離できるだけの状態変化を見せた。
- 手書き数字の画素の数を増やした場合においては、入力データのそれぞれの行を分割するという手法を取っており、さらに2つの異なるレートを用いて入力することにより精度の向上を図っている。
💬Questions or comments
- 実際に実験を行うとしたらメモリスタの時定数と入力パルスの間隔が適切でないと飽和してしまう可能性があるため、それらを適切に調節する必要があると考えられる。どういった指標をもとに調節したのかが気になった。
- 画像を入力データとしたとき、各行を入力データとして与えているが、一般的な画像認識としては全体を一つのデータとして扱うと思う。列データとしても扱うと書いてあるが、別の改善策があるのではないかと思った。

Title
Conformal quantum dot–SnO2 layers as electron transporters for efficient perovskite solar cells
Minjin Kim, Jaeki Jeong, et al.,
📄Resource https://www.science.org/doi/10.1126/science.abh1885
🔎Points
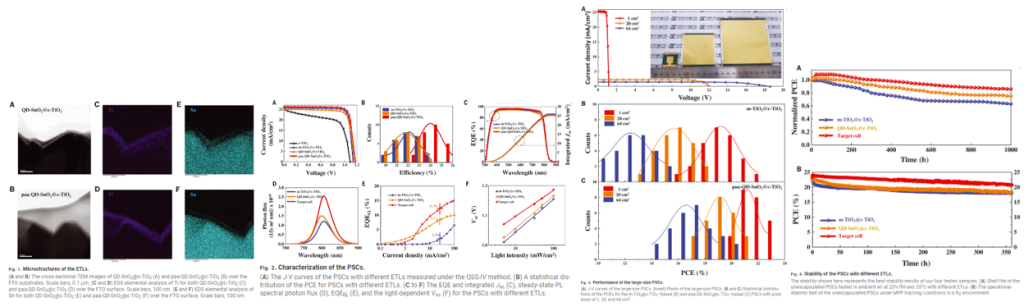
- 一般的に電子輸送層で使用されているメソポーラス酸化チタンをコンパクト酸化チタン上のpaa-QD-SnO2の薄層に置き換えることで, 受光を促進し, ELT-ペロブスカイト界面での非放射再結合を大きく抑制できる.
- 電子選択性コンタクトとしてpaa-QD-SnO2を用いることで、25.7%の電力変換効率と高い動作安定性を持つPSCsが可能になった.
- 64cm2のPSCモジュールの平均電力変換効率がm-TiO2からpaa-QD-SnO2に置き換えることで約30%増加した.
💬Questions or comments
- カプセル化されていないPSCの貯蔵寿命は相対湿度25%RH, 温度は25℃で行われていたが, これらの条件を変更した場合の結果はどうなるのか
- PSCの貯蔵時間と動作安定性のテストを行った際のモジュールサイズが分からなかった.
Title
Title: Plasma steering to avoid disruptions in ITER and tokamak power plants
📄Resource https://arxiv.org/pdf/2101.10138.pdf
🔎Points
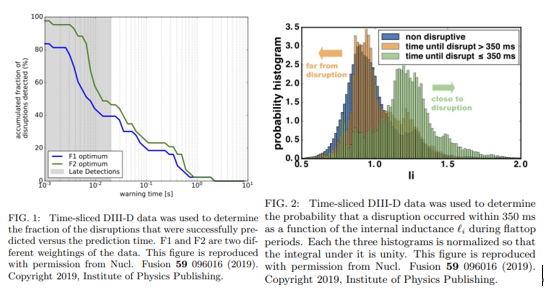
1. This paper addresses the difficulties faced when controlling the plasmas inside a tokamak power plant (power plant discussed in the paper Prf. Sogabe shared)
2. One major problem discussed is danger forecasting. Because of its high plasma current, a reliable method of foreseeing danger is a must. However, papers referenced (such as [8] T. Yokoyama, T. Sueyoshi, Y. Miyoshi, R. Hiwatari,Y. Igarashi, M. Okada, and Y. Ogawa, Disruption Prediction by Support Vector Machine and Neural Network with Exhaustive Search, Plasma and Fusion Research 13, 3405021(2018)) show that most had modest reliability, while also being short sighted.
3. Another problem is the delayed response of the actuators. Even if a decent method of solving 2.’s problem had been found, the delayed response of the actuators may keep them from being effective.
4. Breaking the balance of control will throw the whole system out of control: Literally losing control of the plasma, heat disposition and electrons that strayed away from the system damaging its surroundings
💬Questions or comments
1. As seen from the reference of the paper, it is quite impressive to see that many reinforcement techniques are being implemented to foreseeing dangers, and how these techniques are showing their highly adaptive nature.
2. Despite this paper’s conclusion, will advancement of reinforcement learning methods such as the one introduced in prf. Sogabe’s paper tackle the challenges and make the deployment of these technologies a reality?
3. Papers referenced (especially [8] ~ [14]) are also very interesting topics to read in the future.
Title
Quantum Chemical Calculations to Trace Back Reaction Paths for the Prediction of Reactants
Yosuke Sumiya, Yu Harabuchi, Yuuya Nagata, and Satoshi Maeda*
📄Resource https://doi.org/10.1021/jacsau.2c00157
🔎Points
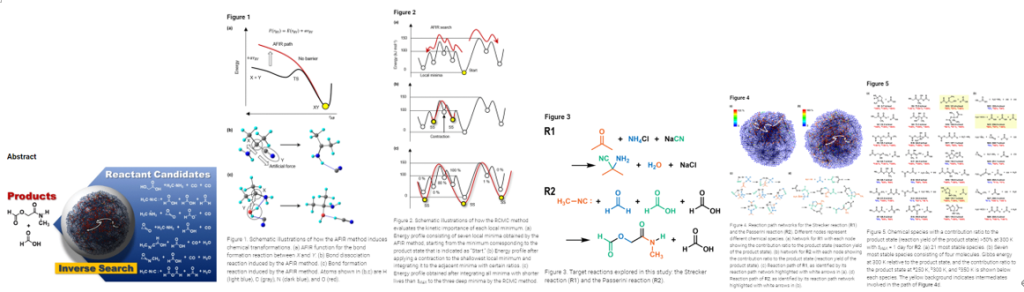
- 目的化合物を合成するための反応経路を第一原理的に計算する手法は反応が複数の素反応の場合から起こる組合せ爆発が問題となっていた。研究グループはこれを抑えて、目的化合物から反応物候補を列挙できる量子化学計算手法を開発した。
- AFIR(Artificial Force Induced Reaction)により探索を行い、目的の反応物の寄与率(反応収率)が閾値の0.1%以下になるような反応物の探索を打ち切ることで組合せ爆発を抑えた探索を実現している。その際、RCMC法(速度定数行列縮約)で短時間の熱平衡を再現し、その際の生成物状態を主成分とする超状態に対する寄与率が、そのまま反応収率に対応していることを利用して計算を行なっている。
- 本研究では、このAFIR/RCMC複合法を用いてStrecker反応とPasserini反応という二つの既知反応に適用しそれぞれの生成物を入力とした。結果としては、反応ネットワークを構築でき、よく知られた反応機構を経て生成される経路が特定されたほか、それ以外にも対応する生成物を高収率で与える反応物候補が多く予測された。
💬Questions or comments
- 熱平衡状態における超状態とは何なのかといった点が不勉強のため分かりづらく、RCMC法の概念だけの理解にとどまった。
- 実験データベースを活用したAI手法による反応設計法は盛んに研究されているが、この研究グループの手法は実験データには頼らず自動探索によって解析しているのが面白いと感じた。AIの手法だとどうしても実験データベースに頼ってしまう形になるので、本手法は知られていない反応物に対しても探索を行えている点で優れていると感じた。